Multivariate Random Variables

Learning Objectives
- Explain how a probability matrix can be used to express a probability mass function (PMF).
- Compute the marginal and conditional distributions of a discrete bivariate random variable.
- Explain how the expectation of a function is computed for a bivariate discrete random variable.
- Define covariance and explain what it measures.
- Explain the relationship between the covariance and correlation of two random variables and how these are related to the independence of the two variables.
- Explain the effects of applying linear transformations on the covariance and correlation between two random variables.
- Compute the variance of a weighted sum of two random variables.
- Compute the conditional expectation of a component of a bivariate random variable.
- Describe the features of an 𝑖𝑖𝑑 sequence of random variables.
- Explain how the 𝑖𝑖𝑑 property is helpful in computing the mean and variance of a sum of 𝑖𝑖𝑑 random variables.
- Video Lecture
- |
- PDFs
- |
- List of chapters
Chapter Contents
- Introduction
- Bivariate Random Variable
- Joint Probabilities
- Marginal Distributions
- Independence
- Conditional Distributions
- Independence
- Expectations
- Moments
- Variances And Covariance
- Covariance And Correlation
- Shifting And Scaling Effects On Covariance
- Covariance – Properties
- Covariance Matrix
- Correlation Interpretation
- Correlation And Portfolio Diversification
- Covariance, Correlation, And Independence
- Cross Central Moments
- Conditional Expectations
- Conditional Moments
- Conditional Independence
- Continuous Random Variables
Introduction
- Multivariate random variables extend the concept of a single random variable to include measures of dependence between two or more random variables. Each component of a multivariate random variable is a univariate random variable.
- Multivariate random variables are vectors of random variables. For example, a bivariate random variable 𝑋 would be a vector with two components: and
. Similarly, its realization (i.e., x) would have two component values as well:
and
. Treated separately,
and
- Just like their univariate counterparts, multivariate random variables are like in that they can be discrete or continuous. Similarly, both types of random variables are denoted with uppercase letters (e.g., X, Y, or Z).
- The probability mass function (PMF) for a bivariate random variable returns the probability that two random variables each take a certain value. This means that plotting these functions requires three axes:
Bivariate Random Variable
- The PMF of a bivariate random variable is given by
- An example of a discrete bivariate random variable is the trinomial distribution, which is the distribution of n independent trials where each trial produces one of three outcomes.
- The two components of a trinomial are
and
, which count the number of realizations of outcome 1 and 2. The count of the realizations for outcome 3 is given by
.
- For example, when measuring the credit quality of a diversified bond portfolio, the 𝑛 bonds can be classified as investment grade, high yield or unrated. In this case,
- The trinomial PMF has three parameters:
n (i.e., the total number of experiments),
, (i.e., the probability of observing outcome 1), and
(i.e., the probability of observing outcome 2).
Because these outcomes are exclusive, the probability of outcome 3 is simply
•The PMF of a trinomial random variable is
- The CDF of a bivariate variable is a function returning the total probability that each component is less than or equal to a given value for that component, so that:
where contains the values that
may take as long as
, and
is similarly defined only for
.
Joint Probabilities
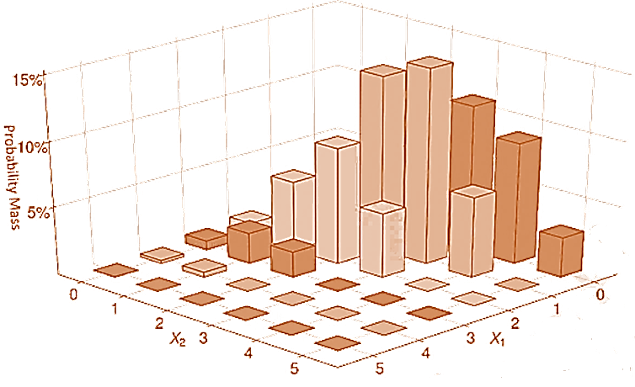
- Discrete distributions defined over a finite set of values can be described using a probability matrix, which relates realizations to probabilities. In other words, it is a tabular representation of a PMF.
- For example, let the return on a company’s stock be related to the rating given to the company by an analyst. Assume that the stock can only have three possible returns: 0, 5%, or -5%. Analyst ratings can be positive, neutral, or negative, and are labeled 1, 0, or -1 (respectively).
- Discrete distributions defined over a finite set of values can be described using a probability matrix, which relates realizations to probabilities. In other words, it is a tabular representation of a PMF.
- For example, let the return on a company’s stock be related to the rating given to the company by an analyst. Assume that the stock can only have three possible returns: 0, 5%, or -5%. Analyst ratings can be positive, neutral, or negative, and are labeled 1, 0, or -1 (respectively).
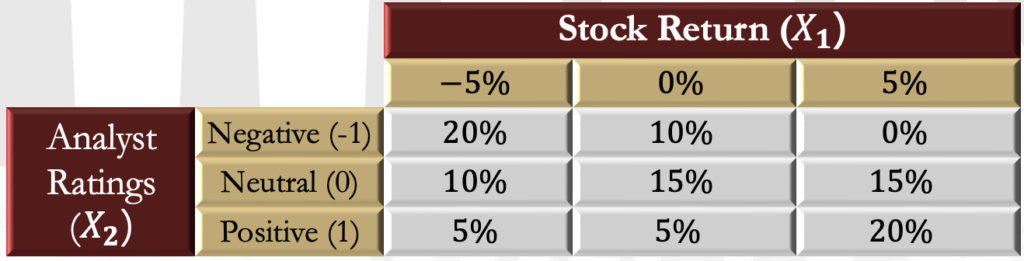
Marginal Distributions
- The PMF describes the joint distribution of the two components
. It is also possible to examine each variable individually.
- The distribution of a single component of a bivariate random variable is called a marginal distribution. This distribution contains the probabilities of realizations of
and its PMF denoted by
. Marginal PMF is simply a univariate PMF.
- The marginal PMF of
. The marginal PMF is defined as:
- When a PMF is represented as a probability matrix, the two marginal distributions are computed by summing across columns (which constructs the marginal distribution of the row variables) or summing down rows (which constructs the marginal PMF for the column variables).
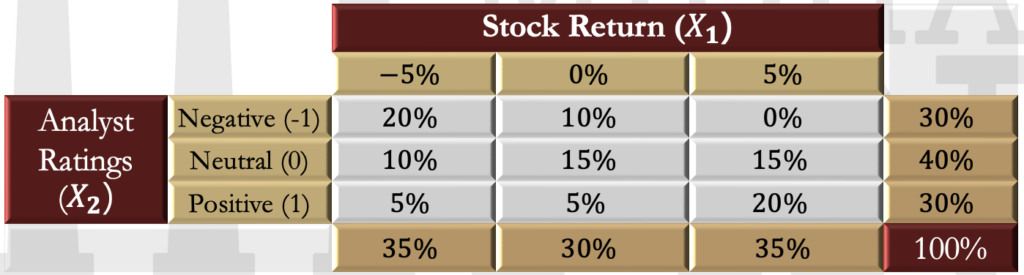
| Stock Return (X1) | fX2(X2) | ||||
| −5% | 0% | 5% | |||
| Analyst Ratings (X2) | Negative (-1) | 20% | 10% | 0% | 30% |
| Neutral (0) | 10% | 15% | 15% | 40% | |
| Positive (1) | 5% | 5% | 20% | 30% | |
| 35% | 30% | 35% | 100% | ||
•The marginal CDF is defined in a natural way using the marginal PMF so that measures the total probability in the marginal PMF less than
Independence
- The components of a bivariate random variable are independent if
- Independence requires that the joint PMF of
be the product of the marginal PMFs.
Conditional Distributions
- The conditional distribution, on the other hand, summarizes the probability of the outcomes for one random variable conditional on the other taking a specific value. The conditional probability of two events was defined as:
- This definition of conditional probability can be applied to a bivariate random variable to construct a conditional distribution. The conditional distribution of
In other words, it is the joint probability of the two events divided by the marginal probability that .
For example, the distribution of stock returns conditional on a positive analyst rating is

Conditional distributions can also be defined over a set of outcomes for one of the variables. For example, consider the distribution of the stock return given that the analyst did not give a positive rating. This set is
The conditional PMF must sum across all outcomes in the set that is conditioned on S={-1,0}, and so:
The marginal probability that is the sum of the (marginal) probabilities of these two outcomes:
- The conditional probability distribution is then:
Independence
- The definition of a conditional distribution can also be rearranged so that the joint PMF is expressed in terms of the marginal PMF and a conditional PMF. For example:
- Equality of the conditional and the marginal PMFs is a requirement of independence. Specifically, knowledge about the value of
) must not contain any information about
Expectations
- The expectation of a function of a bivariate random variable is defined analogously to that of a univariate random variable. The expectation of a function
is a probability weighted average of the function of the outcomes
. The expectation is defined as:
- While
, it may be a function of only one of the components.
- As in the univariate case,
for a nonlinear function
- As an example, consider the following joint PMF:
| 1 | 2 | ||
| 3 | 15% | 10% | |
| 4 | 60% | 15% | |
- Now, consider the function
The expectation of is therefore
Moments
The first moment of X (i.e., the mean E[X]) is the mean of the components
The second moment of X is referred to as the covariance of X. The covariance is technically a 2-by-2 matrix of values, where the values along one diagonal are the variances of , and the terms in the other diagonal are the covariance between
The covariance is a measure of dispersion that captures how the variables move together.
The covariance between is defined as:
Note that it is a generalization of the variance, and the covariance of a variable with itself is just the variance of that variable
Variances And Covariance
- In a bivariate random variable, there are two variances and one covariance.
- It is common to express
as
and
as
. The symbols
are used to denote the standard deviations of
, respectively.
- An alternative abbreviation scheme uses
to indicate the variances of
- The covariance is commonly abbreviated to
in both schemes.
Covariance And Correlation
- Covariance is difficult to interpret because it can take on values from -∞ to +∞. It can be made easier to interpret by standardizing it to produce correlation. It is therefore more common to report the correlation, which is a scale-free measure. Correlation of two variables is obtained by dividing their covariance by their respective standard deviations i.e.
- Correlation measures the strength of the linear relationship between two variables and is always between -1 and 1. When
Shifting And Scaling Effects On Covariance
- Location shifts have no effect on the covariance, whereas the scale of each component contributes multiplicatively to the change in the covariance. Hence,
- Applying location shifts of a and c
AND
rescaling the variables by b and d scales the covariance by bd. i.e.
Using the above, the correlation estimator is scale free:
Covariance – Properties
where
are independent random variables.
i.e. the covariance of a random variableX_1with itself is the variance of X_1.
where a, b, c, d are constants.
if are not independent
Covariance Matrix
- The correlation between two random variables is commonly denoted by ρ (or
to specify that this is the correlation between the components). The covariance can be expressed in terms of the correlation and the standard deviations:
- The variance of each component and the covariance between the two components of X are frequently expressed as a 2-by-2 covariance matrix. The covariance matrix of X is
Correlation Interpretation
- The following table shows the interpretation of different values of correlation
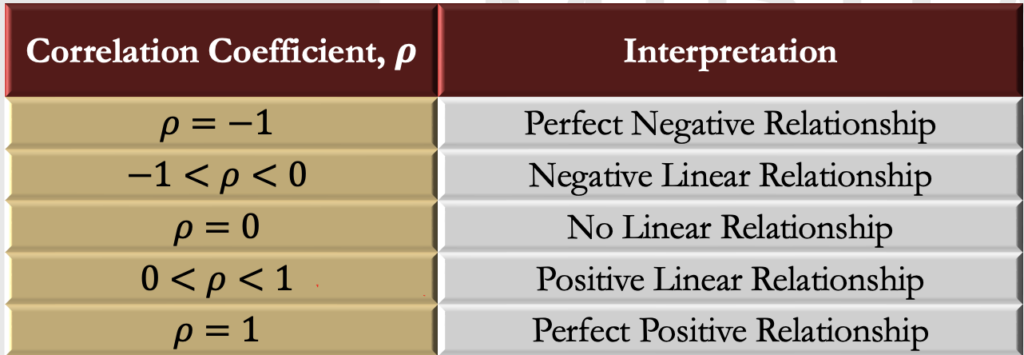
Correlation And Portfolio Diversification
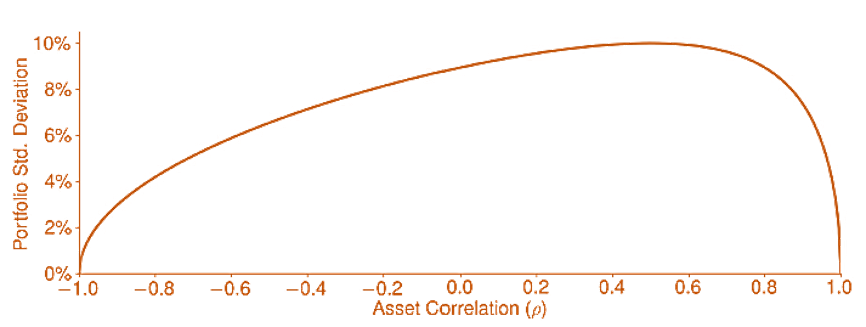
The portfolio standard deviation using the optimal portfolio weight in a two-asset portfolio, where the first asset has a volatility of 20%, the second has a volatility of 10%, and the correlation between the two is varied between -1 and 1.
Covariance, Correlation, And Independence
When two random variables are independent, they must have zero correlation because (by definition) they must contain no information about each other. However, if two random variables have zero correlation, they are not necessarily independent.
Correlation is a measure of linear dependence. If two variables have a strong linear relationship (i.e., they produce values that lie close to a straight line), then they have a large correlation. If two random variables have no linear relationship, then their correlation is zero.
However, variables can be non-linearly dependent. A simple example of this occurs when:
It is known that
If the correlation between two variables is 0, then , so
Hence, the expectation of the product of the two is the product of the expectations when the two variables are linearly independent.
Cross Central Moments
- The concept of covariance can be generalized and cross central moments can be identified.
- The third cross central moment is known as coskewness. If two random variables exhibit positive coskewness they will tend to undergo extreme positive deviations at the same time. Similarly, if two random variables exhibit negative coskewness they will tend to undergo extreme negative deviations at the same time.
- The fourth cross central moment is known as cokurtosis. If two random variables exhibit a high level of cokurtosis they will tend to undergo extreme positive and negative deviations at the same time.
- Coskewness and Cokurtosis are defined by taking powers of the two variables that sum to 3 or 4, respectively. There are two distinct coskewness measures and three distinct cokurtosis measures.
For example, the two coskewness measures are
Like the skewness of a single random variable, the coskewness measures are standardized.
They both measure whether one random variable (raised to the power 1) takes a clear direction whenever the other return (raised to the power 2) is large in magnitude. For example, it is common for returns on individual stocks to have negative coskew, so that when one return is negative, the other tends to experience a period of high volatility (i.e., its squared value is large).
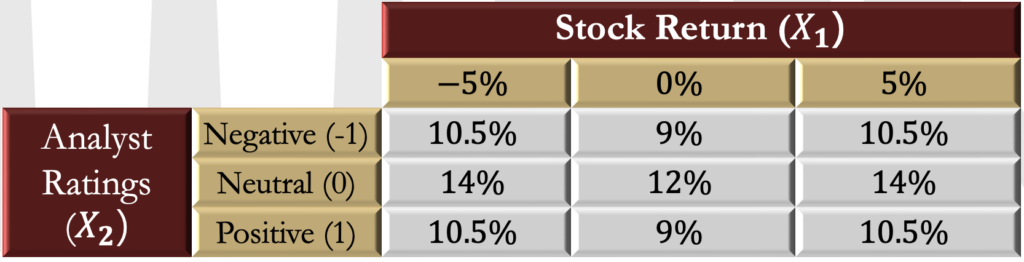
Conditional Expectations
- A conditional expectation is an expectation when one random variable takes a specific value or falls into a defined range of values. It uses the same expression as any other expectation and is a weighted average where the probabilities are determined by a conditional PMF.
- In the previous example, consider the expected return on the stock given a positive analyst rating. The conditional distribution here [i.e.,
] is

- The conditional expectation of the return is
Conditional Moments
- Conditional expectations can be extended to any moment by replacing all expectation operators with conditional expectation operators. For example, the variance of a random variable X_1 is
The conditional variance of given
is

- In the previous example, the standard deviation of the stock return (i.e., the square root of the variance) is
The standard deviation conditional on a positive rating is
Conditional Independence
- As a rule, random variables are dependent in finance and risk management. This dependence arises from many sources, including
- shifts in investor risk aversion,
- cross-asset or cross-border spillovers, and
- crowded portfolio strategies.
- Conditioning is a useful tool to remove the dependence between variables.
- In the previous example, suppose that an investor wants to identify firms that have a conservative management style. This style variable can be labeled Z.
- Now suppose that 12.5% of the companies are in the conservative category and that the probability of the outcomes of stock returns and recommendations based on management style are as in the table below:
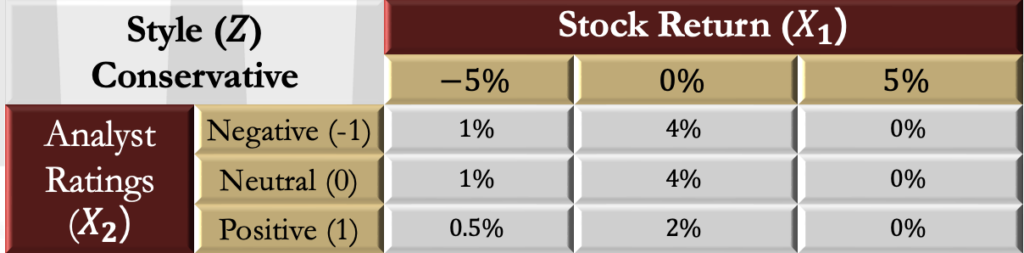
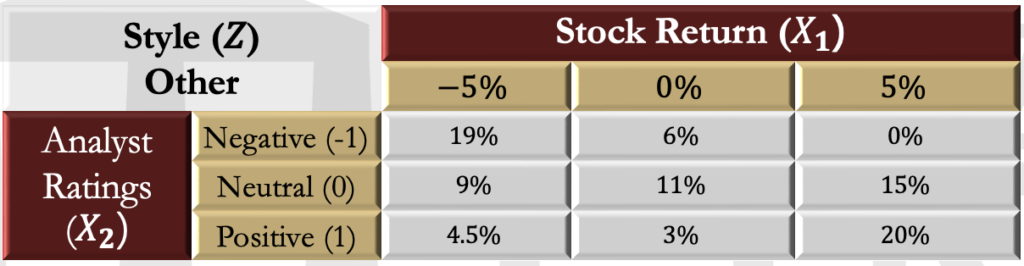
- The overall probabilities are consistent with the original bivariate matrix. For example, there is still a total 20% chance of a negative rating when the stock return is -5%.
- Now consider the bivariate distribution conditional on a company being in this conservative category. As before, each individual probability is rescaled by a constant factor so that the total conditional probability sums to 1. In other words, each value is divided by the probability that the management is conservative (i.e., 12.5%), which is also the sum of the values in the panel.
Continuous Random Variables
- Moving from discrete multivariate random variables to those that are continuous changes little. The most substantial change is the replacement of the PMF with a PDF, and the corresponding switch from sums to integrals when computing expectations. All definitions and high-level results (e.g., the effect of linear transformations on the covariance of random variables) are identical.
- The PDF has the same form as a PMF and is written as
- The probability in a rectangular region is defined as:
- This expression computes the volume under the PDF function in the region defined by
,
,
, and
. A PDF function is always non-negative and must integrate to one across the support of the two components.
The cumulative distribution function is the area of a rectangular region under the PDF where the lower bounds are -∞ and the upper bounds are the arguments in the CDF:
If the PDF is not defined for all values, then the lower bounds can be adjusted to be the smallest values where the random variable has support.
Most continuous multivariate random variables have complicated PDFs. The simplest is the standard bivariate uniform where the two components are independent. The PDF of this random variable is constant:
and the support of the density is the unit square (i.e., a square whose sides have lengths of 1).
The CDF of the standard bivariate independent uniform is
Go to Syllabus
Courses Offered
Popular Courses
FRM Part 1
FRM Part 2

By : Micky Midha
9 Hrs of Videos
Available On Web, IOS & Android
Access Until You Pass
Lecture PDFs
Class Notes

By : Micky Midha
12 Hrs of Videos
Available On Web, IOS & Android
Access Until You Pass
Lecture PDFs
Class Notes

By : Micky Midha
257 Hrs Of Videos
Available On Web, IOS & Android
Access Until You Pass
Complete Study Material
Quizzes,Question Bank & Mock tests

By : Micky Midha
240 Hrs Of Videos
Available On Web, IOS & Android
Access Until You Pass
Complete Study Material
Quizzes,Question Bank & Mock tests

By : Shubham Swaraj
Lecture Videos
Available On Web, IOS & Android
Complete Study Material
Question Bank & Lecture PDFs
Doubt-Solving Forum